Jobs:
Jobs are iterative processes that call into an external service to query for updated data. The data is then sent to the appropriate pipeline for processing. Each time a job runs the query uses an updated timestamp to retrieve only the data that has changed since the last time the job ran. Jobs can be configured to run at a defined interval from 5 minutes to 24 hours.
Job Types:
There are currently 2 main job types, more will be added in the future.
- Salesforce Query
- This job type is used to query salesforce using SOQL queries. It is a powerful tool to pull data into a pipeline
- Http Request
- This job type is used to access web based APIs that take parameters as input into the data query
You can add a new job by clicking the “+ Add Job” button. Choose a name, a job type, and the desire interval for the job:
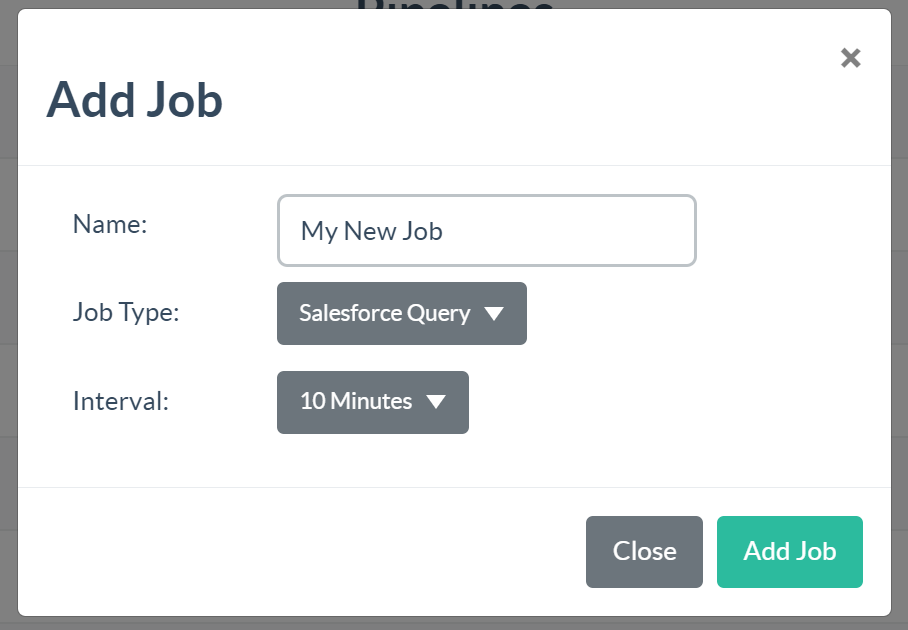
Click “Edit” next to a job to navigate to the job editor. There is a different editor for each job type.
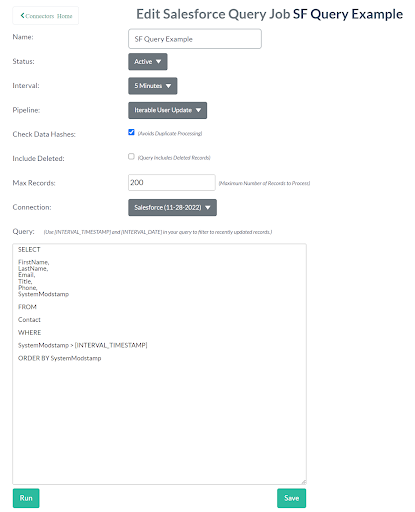
Salesforce Query Job Editor:
The Salesforce Query Job editor has the following parameters
- Name
- A user defined name for the job
- Status
- The job can be set to active or inactive
- Interval
- The job will run at this interva, can be set from 5 minutes to 24 hours
- Pipeline
- The pipeline to send records to for processing
- Check Data Hashes
- If enabled this will create a hash of each found record and to check against subsequent runs so we don’t process the same data more than once.
- Include Deleted
- If enabled this will include deleted records in the salesforce database in the query. Default is disabled.
- Max Records
- The maximum number of records to process for each run of the job. If more than this number of records are found the job will keep track of the last updated timestamp of the last processed record and start the next job from there.
- Connection
- Choose the integration connection to use for this job.
- Query
- This is the SOQL query used to retrieve records from Salesforce. There are two special merge tags you can use in the query to ensure only updated data is retrieved. The [INTERVAL_TIMESTAMP] tag will be replaced with either the last run time of this job, or the last processed record if the prior job hit the max records value. You can also use [INTERVAL_DATE] if you only want the date component of this timestamp.
- We strongly recommend including the SystemModstamp field in your query. If you don’t then the job won’t be able to track the last processed item’s modification timestamp.
Http Job Editor:
The Http Job Job editor has the following parameters
- Name
- A user defined name for the job
- Status
- The job can be set to active or inactive
- Interval
- The job will run at this interva, can be set from 5 minutes to 24 hours
- Pipeline
- The pipeline to send records to for processing
- Check Data Hashes
- If enabled this will create a hash of each found record and to check against subsequent runs so we don’t process the same data more than once.
- Include Deleted
- If enabled this will include deleted records in the salesforce database in the query. Default is disabled.
- Max Records
- The maximum number of records to process for each run of the job. If more than this number of records are found the job will keep track of the last updated timestamp of the last processed record and start the next job from there.
- Connection
- Choose the integration connection to use for this job.
- Request URL
- The URL endpoint to send the request
- Request Method
- The Http method to use on the request GET,POST etc.
- Request Body Type
- Set this to the appropriate request body type needed for the URL endpoint
- Request Body
- This is the payload of the http request
- Headers
- You can add any additional headers required by the URL endpoint
- Response Body Type
- This determines how the response will be parsed by the system
- Single Record
- If enabled, this tells the system to treat the response as a single record, as opposed to a collection of records
- Path to Records
- Assuming a JSON response this is the JSON Path to the collection of records
- Paging Enabled
- Some APIs have a paging ability to retrieve data in batches. Enable this option to use paging
- Page Size
- The page size to use
- Page Parameter
- This is a user defined merge tag that is used for paging. The URL, Request Body, and Headers will have this tag replaced by the appropriate page
- Page Size Parameter
- This is a user defined merge tag that is used for paging. The URL, Request Body, and Headers will have this tag replaced by the appropriate page size
You can optionally filter returned records clicking the “Item Filter” button. Here you can define conditions that must be satisfied for the record to be sent to the configured pipeline. This can be useful if the API does not provide native filtering capabilities.

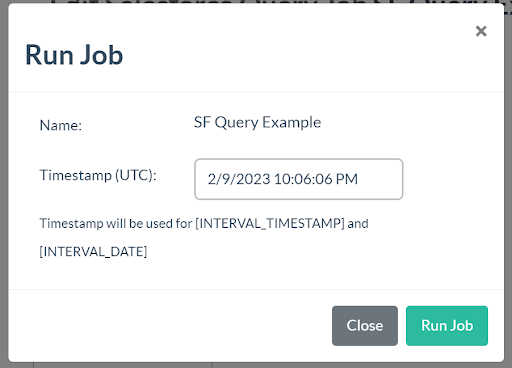
Run Job
You can run a job manually at any time by clicking the “Run” button. This will pop up a window asking to set the [INTERVAL_TIMESTAMP] of your choosing. This will then direct you to the job log detail page.
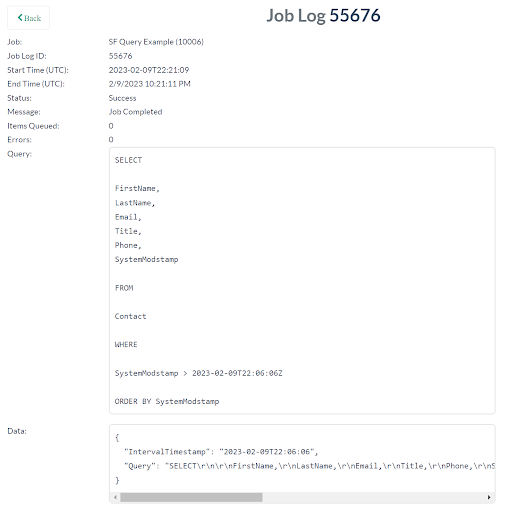
Job Activity:
You can view job activity from the main page by clicking the “Activity” button next to the job.
You can also see detailed logs about how many items were queued and the queries run (but not the records themselves) by clicking the “Logs” button.